【Python爬虫实战】为何如此痴迷Python?还不是因为爱看小姐姐图
本文共 1516 字,大约阅读时间需要 5 分钟。
目录
爬取目标
网址:
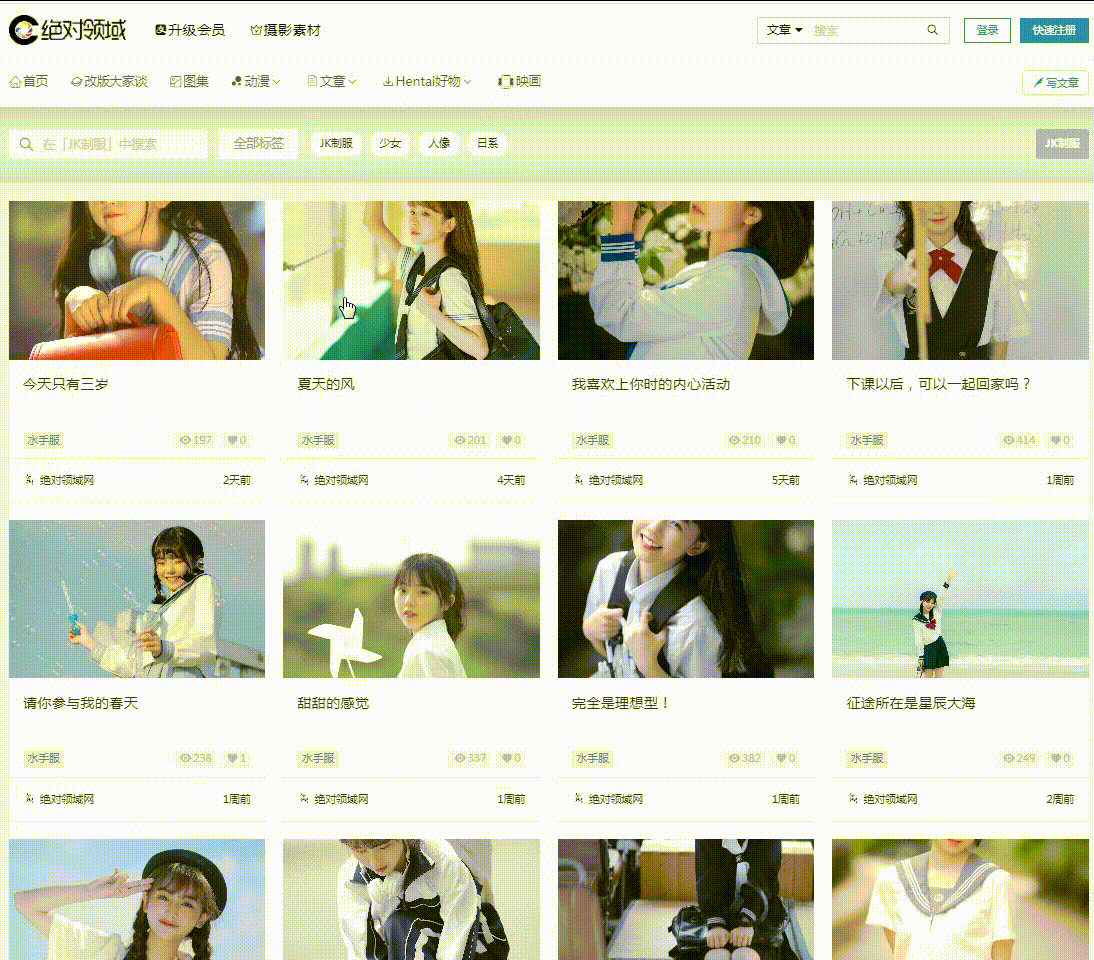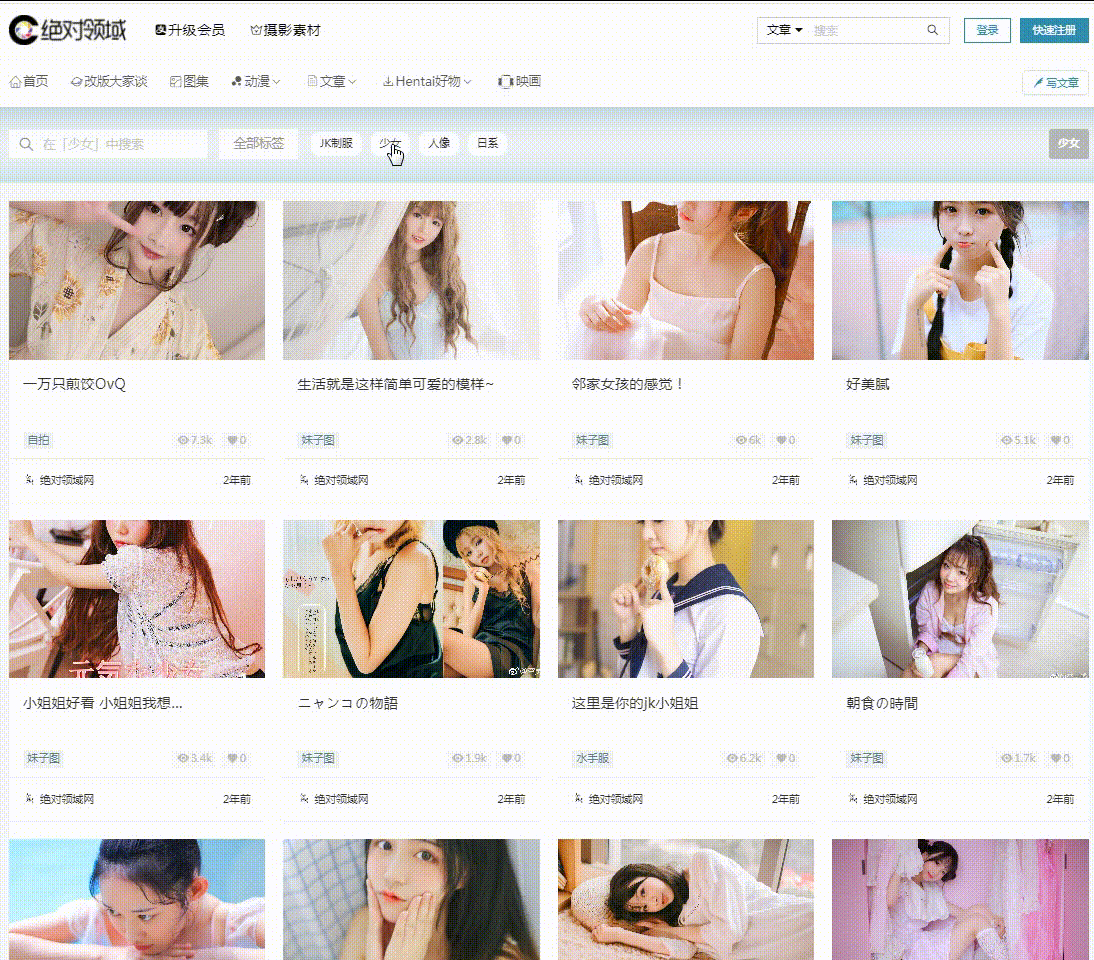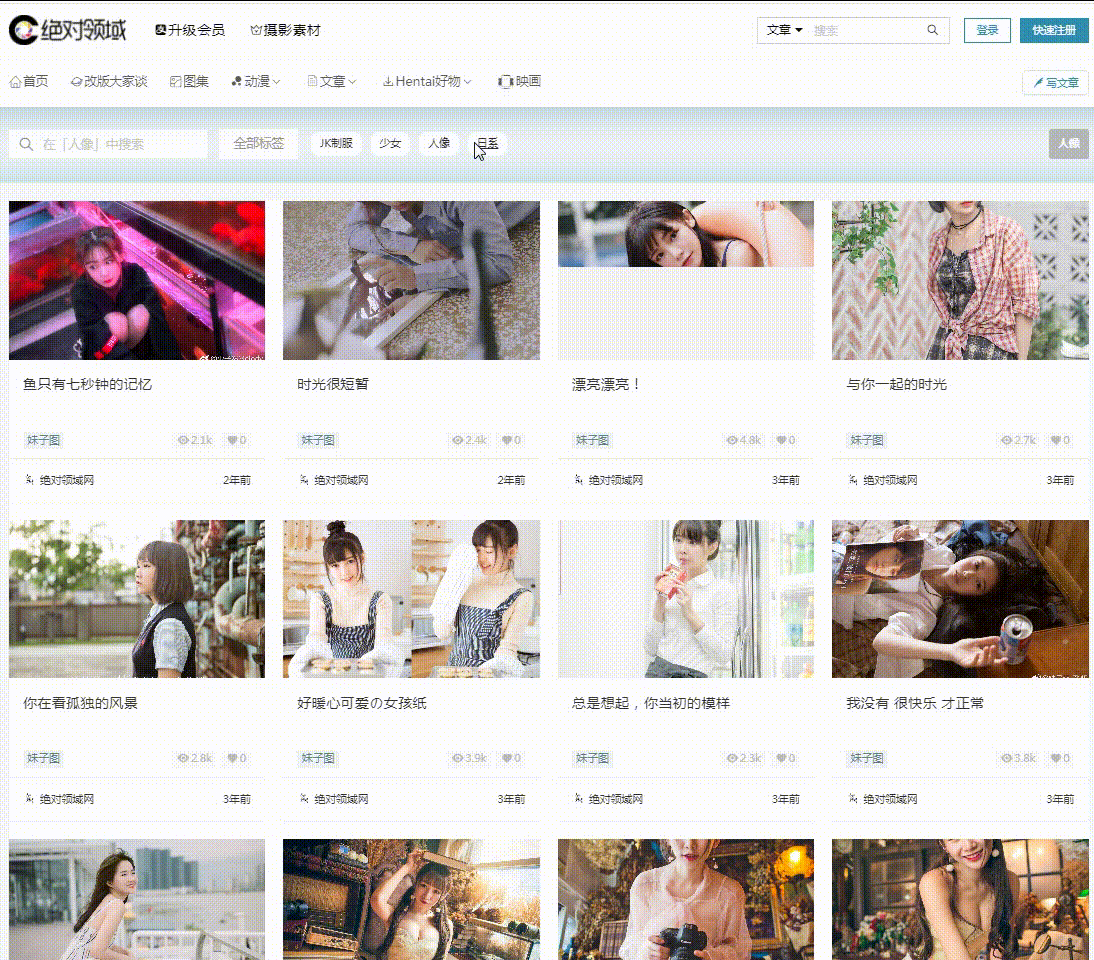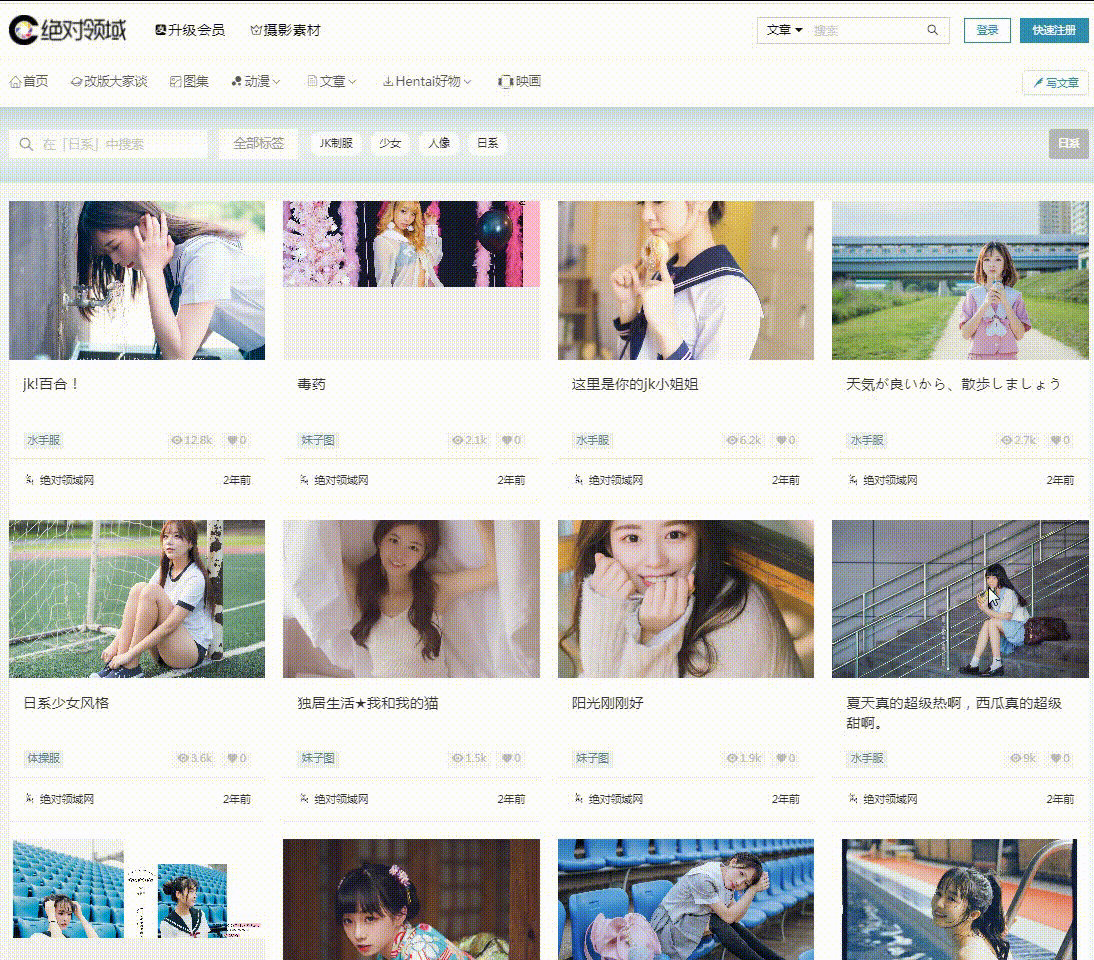
工具使用
开发环境:win10、python3.7
开发工具:pycharm、Chrome 工具包:requests,lxml项目思路解析
选取你对应的图片分类
 根据分类信息提取到没有图片的超链接,提取出A标签的跳转地址以及图片的标题名字
根据分类信息提取到没有图片的超链接,提取出A标签的跳转地址以及图片的标题名字 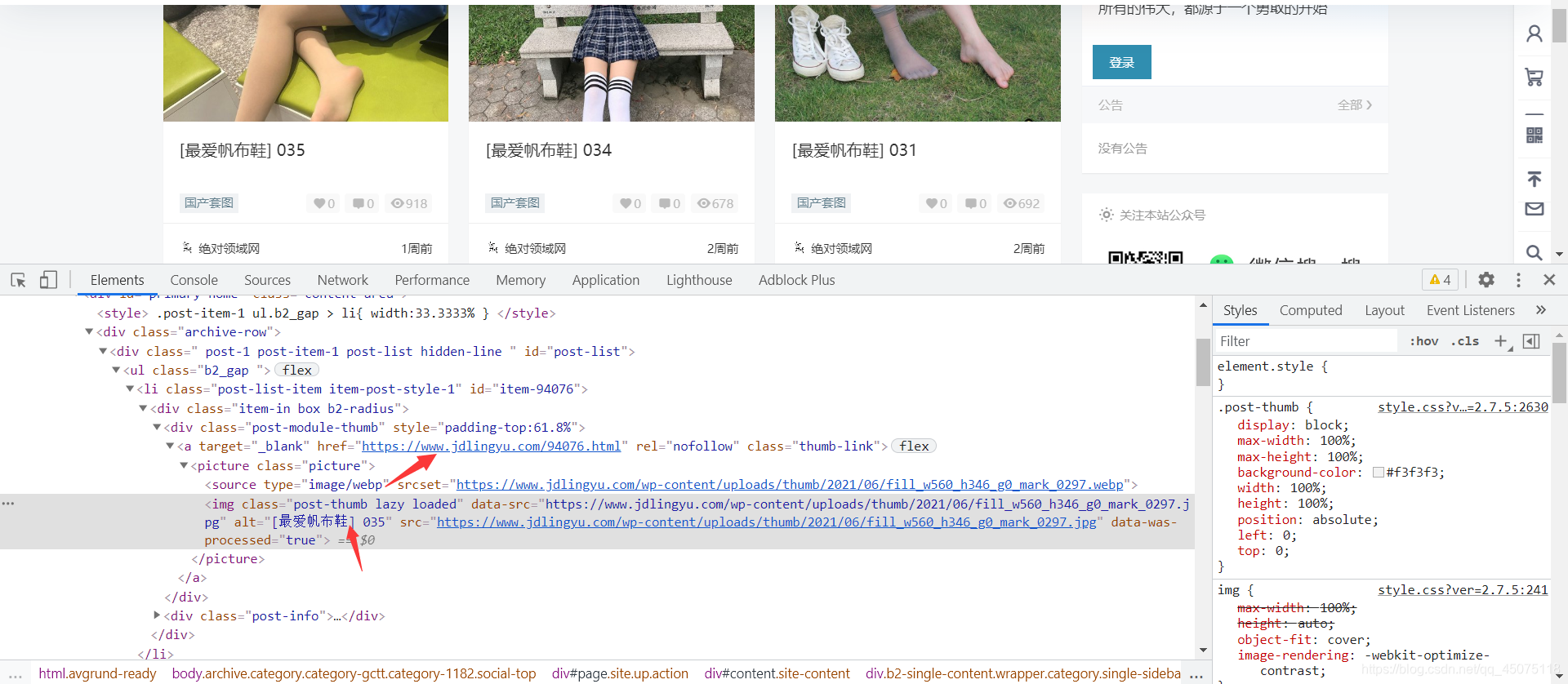
def get_url(start_url): response = requests.get(start_url, headers=headers).text data = etree.HTML(response) new_url = data.xpath('//div[@class="post-module-thumb"]/a/@href') for url in new_url: yield url 进入详情页面,xpath提取详情页面所有的图片地址:
 发送图片数据请求,保存对应图片数据信息
发送图片数据请求,保存对应图片数据信息 简易源码分享
import requestsfrom lxml import etreeheaders = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}def get_url(start_url): response = requests.get(start_url, headers=headers).text data = etree.HTML(response) new_url = data.xpath('//div[@class="post-module-thumb"]/a/@href') for url in new_url: yield urldef get_img(url): response = requests.get(url, headers=headers).text img_data = etree.HTML(response) img_url = img_data.xpath('//div[@class="entry-content"]/img/@src') for img_url in img_url: name = img_url.split("/")[-2] + img_url.split("/")[-1] result = requests.get(img_url).content with open("图片/" + name, "wb")as f: f.write(result) print("正在下载", name)if __name__ == '__main__': for i in range(1, 3): start_url = "https://www.jdlingyu.com/tuji/hentai/gctt/page/{}".format(i) html_url = get_url(start_url) for url in html_url: get_img(url) 
君羊号:【881744585】欢迎加入《广告勿加,不然你做啥啥不赚钱》最后祝大家学业有成,技术能力能越来越好,收入也越来越多

转载地址:http://dxuef.baihongyu.com/
你可能感兴趣的文章
单元测试需要具备的技能和4大阶段的学习
查看>>
【Loadrunner】【浙江移动项目手写代码】代码备份
查看>>
Python几种并发实现方案的性能比较
查看>>
[Jmeter]jmeter之脚本录制与回放,优化(windows下的jmeter)
查看>>
Jmeter之正则
查看>>
【JMeter】1.9上考试jmeter测试调试
查看>>
【虫师】【selenium】参数化
查看>>
【Python练习】文件引用用户名密码登录系统
查看>>
学习网站汇总
查看>>
【Python】用Python打开csv和xml文件
查看>>
【Loadrunner】性能测试报告实战
查看>>
【面试】一份自我介绍模板
查看>>
【自动化测试】自动化测试需要了解的的一些事情。
查看>>
【selenium】selenium ide的安装过程
查看>>
【手机自动化测试】monkey测试
查看>>
【英语】软件开发常用英语词汇
查看>>
Fiddler 抓包工具总结
查看>>
【雅思】雅思需要购买和准备的学习资料
查看>>
【雅思】雅思写作作业(1)
查看>>
【雅思】【大作文】【审题作业】关于同不同意的审题作业(重点)
查看>>